Relational and Document DBs
One of the most interesting discussions to have with people, notably those with traditional database experience, is that of the relationship between an off the shelf RDBMS and some modern NoSQL document stores.
What makes this discussion so interesting is that there's invariably a lot of opinion driven from, often very valid, experience one way or another. The truth is that there simply isn't a silver-bullet database solution and that by better understanding the benefits and limitations of each, one can make vastly better decisions on their adoption.
From a Crow's Height
At a very high level, there are roughly four camps on the topic, three if you don't count the astronomical majority of the population who couldn't care less.
Those with extensive SQL experience will preach the virtues of a strictly defined schema, data normalization while eschewing the complexities that those features impose on their consumers. Some will reference ACID and point out, quite correctly, that many modern NoSQL document stores do not strictly adhere to those requirements.
On the other side of the fence, advocates of NoSQL document stores will often quote the potential gains to be had in velocity as a result of removing the need for structured schema migrations. They will point out that by avoiding relationships, or limiting them to primary keys as some graph databases do, you can more easily horizontally scale your data. A few will point out that, most, provide analogous guarantees to ACID within their domain, often providing document or field level atomicity in leu of transactions.
The final group is one you will hopefully be able to count yourself among when you're done reading this post. They look at the data representations, domain requirements and, almost without fail, their data consumers long before they make a decision on the type of database they intend to use. Their priority is on how best to persist their data while minimizing their development and operational costs and maximizing the value they get out of a solution.
Scaling Complexity
Complexity is an interesting topic and one which is often overlooked or assumed to be omnipresent in any system. The assumption that it will be present often leads people to disregard it when making a decision, rather than giving it the attention it is due.
Of potentially more importance than initial complexity is your ability to scale it to meet your use cases as they will evolve over time. In many applications the data model represents the core of the application's problem domain. If you "solve" the data model problem, the majority of your task is already complete.
In some cases, this is taken to the extreme - with the entire system being built around its data model. You'll tend to find this in large record keeping systems such as a hospital's patient database.
On the other end of the scale, you'll find applications which primarily act as coordinators between different systems. In these services the code and business logic define the problem domain, with the underlying data models simply being a means to transport some transient information between the service's abstractions and clients.
These two use cases demand an entirely different development approach, place an emphasis on different skill sets within your team and are, in many cases, better suited by different design and development approaches.
In the former case, where your data model defines the problem domain, a waterfall approach to the problem (at least on the data model side) will often serve your team far better than a more evolutionary schema. These schemas will be developed by DBAs with extensive understanding of the problem domain and will dictate how the application functions.
In the latter case, the application's functionality is far more important than the way it stores data and should be prioritized. This leads to the adoption of datastores which support these evolutionary schemas or the use of tools which patch that functionality onto more static datastores. In these environments an Agile approach to schema design, backed by a set of practical guidelines and sound advice from consulting DBAs will often realize better gains.
Data Locality
In a document datastore, the presence of most data in a single document removes much of the burden on the datastore when it comes to querying and returning that data. Specifically, it reduces the number of operations that the database needs to do to answer questions like "Where does Charles live?". In addition to reducing the number of operations required, they also enable easy parallelization across multiple machines, making the process of scaling to meet demand far less painful.
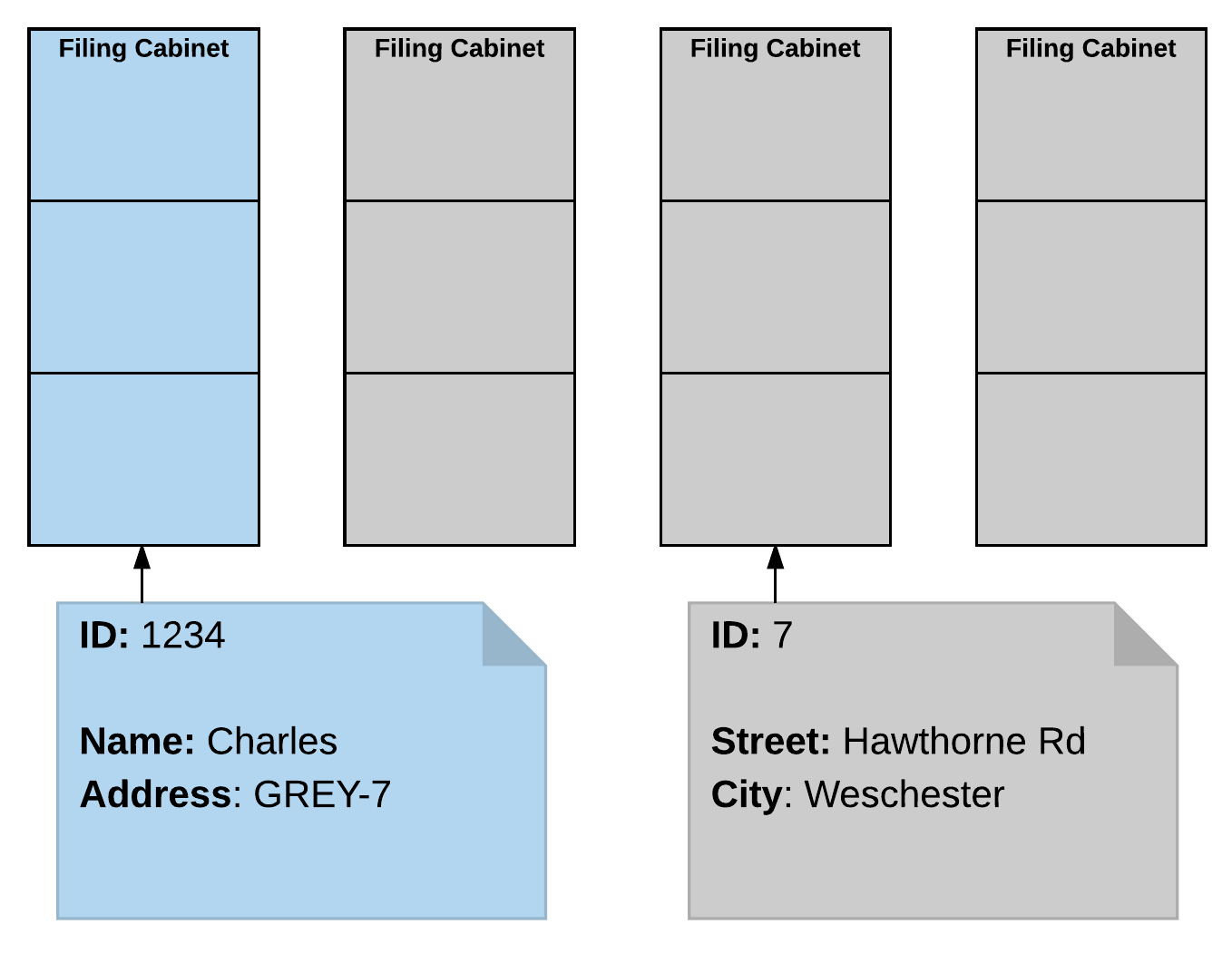
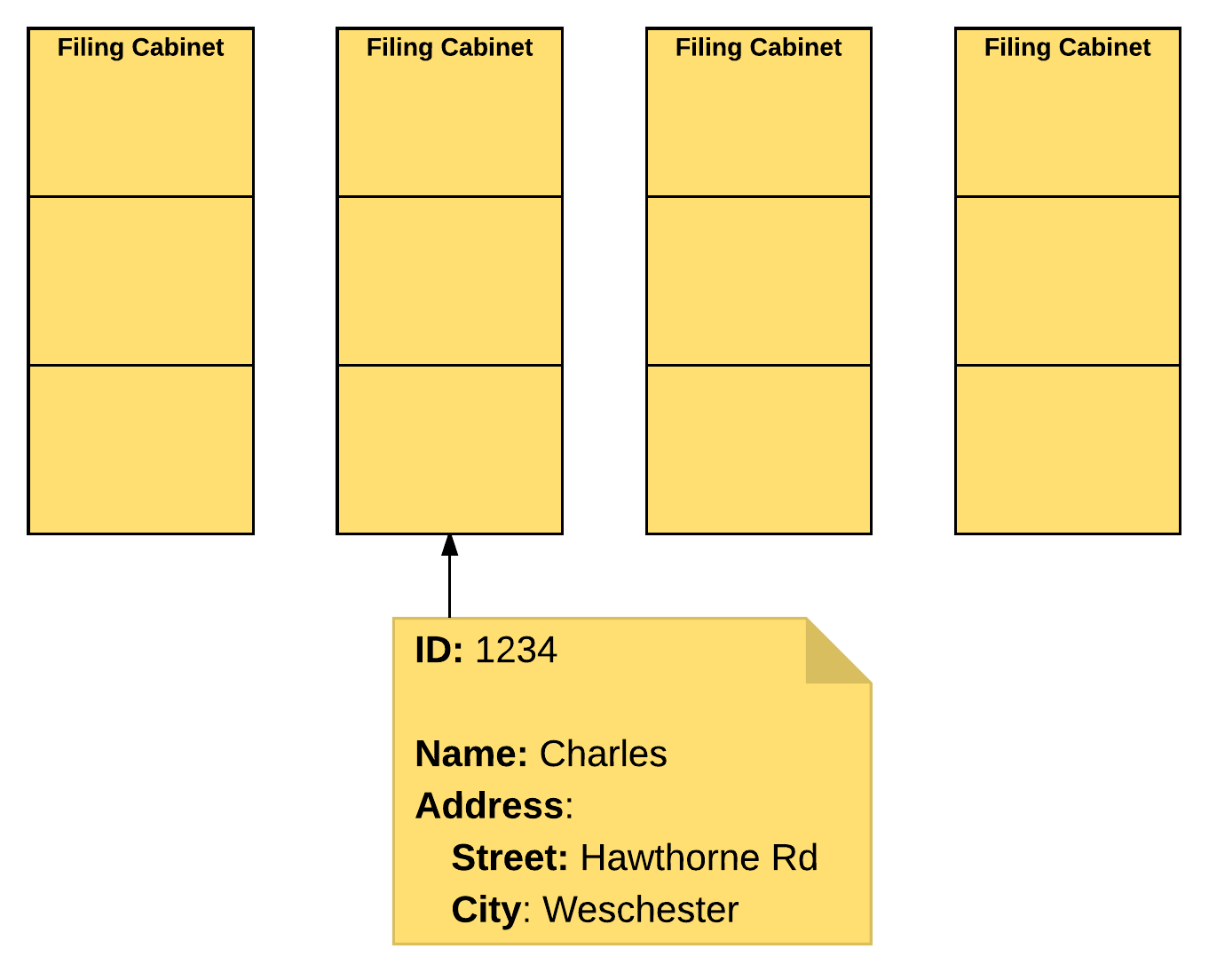
Let's take a real world example to showcase this. Assume we've got a couple of filing cabinets in our office. These cabinets hold the details of our various customers and in the relational case we've colour coded them to show what type of info they hold, but when you want to know where Charles lives you need to first find him in the blue cabinet, check his address and then look through the grey cabinets to answer your question. On the other hand, in the document case you simply find Charles and the data is in his file.
Now imagine the chaos you'd have if half of your grey cabinets were in another office and there were 100 people all trying to answer those questions. Even if you know which office has Charlie's file, how could you possibly coordinate an efficient search for his address.
This is exactly the problem that document databases solve so well.
Schema Ownership
Schema ownership is one of the primary practical differences between document and relational datastores and one of the large motivators for selecting one over another.
When we discuss schema ownership, what we're referring to is who controls how the schema is structured. In most cases this can be split into two categories, consumer driven and backend driven.
It is important to realize that relational databases originated in an era of waterfall design, comprehensive specifications and infrequent releases. In this environment, the need for a reliable, consistent and provable storage medium was immense. Emphasis was placed on design paradigms like Normalization which mapped problems onto UML diagrams elegantly and consistently. Relational databases presented a means to convert those UML diagrams directly into a persistence structure which (if designed well and used correctly) could provably guarantee the consistency of your data.
When using an RDBMS, you must embrace the concept that data is the most important part of your stack and be prepared to have your application take second place.
In this environment, RDBMSes excel. They provide designers and developers with a consistent set of expectations and a known path from a full specification to a functional data layer.
Where this approach doesn't work anywhere near as well is in an environment where your data model rapidly evolves as your application develops, or even as your application is configured. That isn't to say that these problems can't be solved by RDBMSes, but they place a burden on the consumer to provide them with a complete, structured definition of the data they will be storing.
The Document Paradigm
Enter the document approach to data persistence. Certainly nothing new, it offers some interesting properties not present in the relational model. Specifically, by treating data as a relatively dumb blob with a flexible structure you make it possible for many different models to be represented.
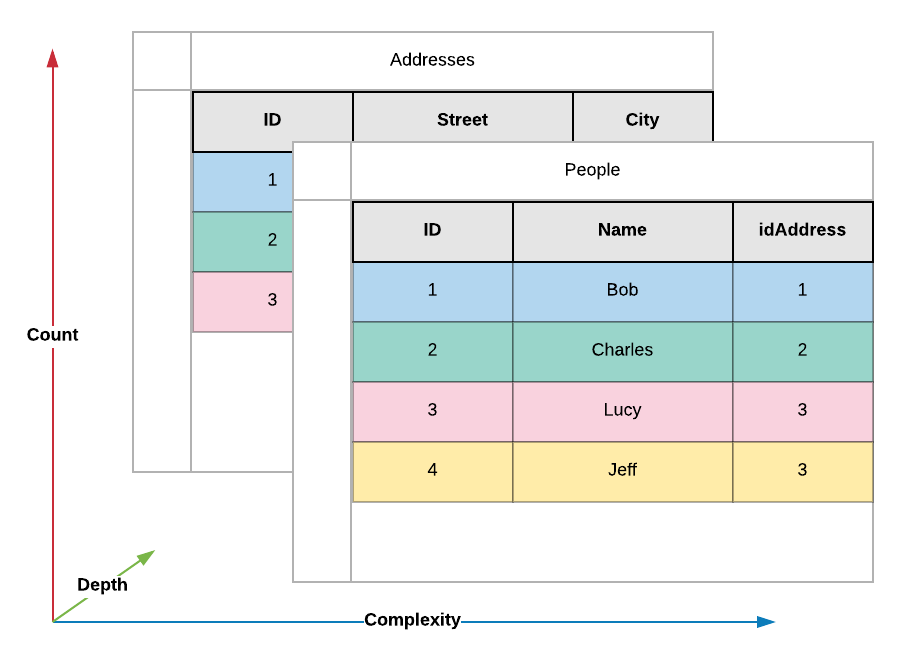
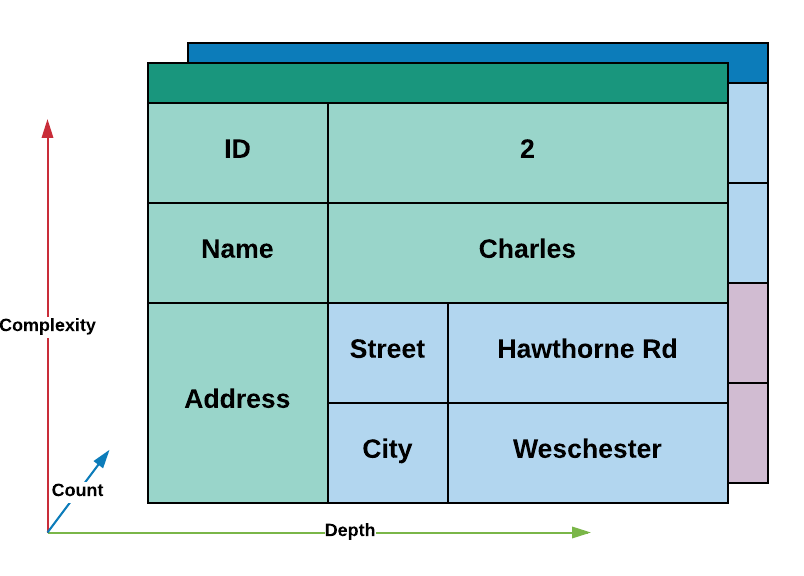
This contrasts with the tabular nature of most relational databases, where you are limited to a single dimension of complexity. This can be expanded, to a degree, through the use of relationships however the data your consumer deals with at the end of the day is always a flat list of fields.
While there are some models which can map to this directly, the majority of development emphasises the separation of information into isolated components. This places the need for mapping data from a one-dimensional format into two-dimensional data structures on the consumer.
Conversely, a document store is capable of representing two dimensional data natively and can, in many cases, alleviate or remove the need to map this data from one form to another within the consumer.
This shift immediately removes a significant amount of complexity from the consumer and places the responsibility of defining the ideal schema on the consumer itself. The result is schemas which are often far better suited to the way that the consumer makes use of data.
Another interesting benefit of this approach is that it places the emphasis on the application or service rather than the data itself. While there are certainly use cases where this is not the correct balance, there are many others in which it is.
Primarily, these use cases tend to be ones where the consumer provides a service through a well defined API. By moving the responsibility for defining the data schema from your data layer into the service, you enable the API to drive the schema. This subtle change makes a world of difference when it comes to how APIs are designed - rather than designing your API to match your ideal data schema, you design your schema to match the ideal API.
By allowing your API's design direct control over your data schema, you enable the delivery of higher quality interfaces with lower implementation complexity.
Red Flags
There are a number of red flags one should keep in mind when making a decision. Unfortunately, for all the common ground shared by relational and document databases, there are things that each does significantly better than their competition.
While the presence of these red flags may not be a reason to abandon a technology completely, they are reasons to critically evaluate whether it represents the best choice given the circumstances.
One to Many Relationships
The first red flag is 1-* (One to Many) relationships. Put quite simply, document databases do not handle this case well in general. The reason for this is that a document database has two approaches to solving the problem.
The first option and most general is to place the responsibility for associating data on the consumer. In this configuration, documents on the secondary (many) side of the relationship store the ID of the document on the primary (one) side of the relationship. As a consequence of the lack of relational constraints, this approach makes it possible to have documents which reference non-existent entities, placing an additional burden on the consumer.
The alternative solution is to store all secondary-side data within an array-like data structure on the primary-side document. This has the benefit of removing the need for the consumer to manage joins and handle missing entities, however it comes at the cost of document size. For use cases where your secondary data is bounded and small, this option works well. For others, you should view 1-* relationships as a significant red flag.
Graph Relationships
Graph relationships, in which you ask questions like "how many relationships exist between these two entities?" or "find the shortest path between two nodes" are one of the use cases which will cripple databases not designed to work with relationship graphs.
While some graph databases are also document databases, the reverse doesn't necessarily hold true and you should be particularly careful around blindly solving this problem with either a document or relational database without explicit graph support.
Dynamic Data
Document databases are very well suited to situations where the exact data you store changes structure during execution. There are extreme examples which demonstrate examples which cannot be replicated by relational databases, however most real world use cases can indeed be duplicated in an RDBMS. The specific reason one would opt to use a document datastore to address this requirement is due to the low complexity and minimal maintenance cost of doing so.
Let's take an example of an audit log which associates metadata about the transaction with each entry. In the relational case we must design the schema for our structured data, a common cost between both document and relational, however for unstructured data like request bodies, the list of affected entities (and their state at the time) and any other details which are not necessarily the same between each log entry, one must either create a number of individual models to represent each possible configuration, or one must fall back on storing blob data which cannot be indexed, effectively queried or aggregated.
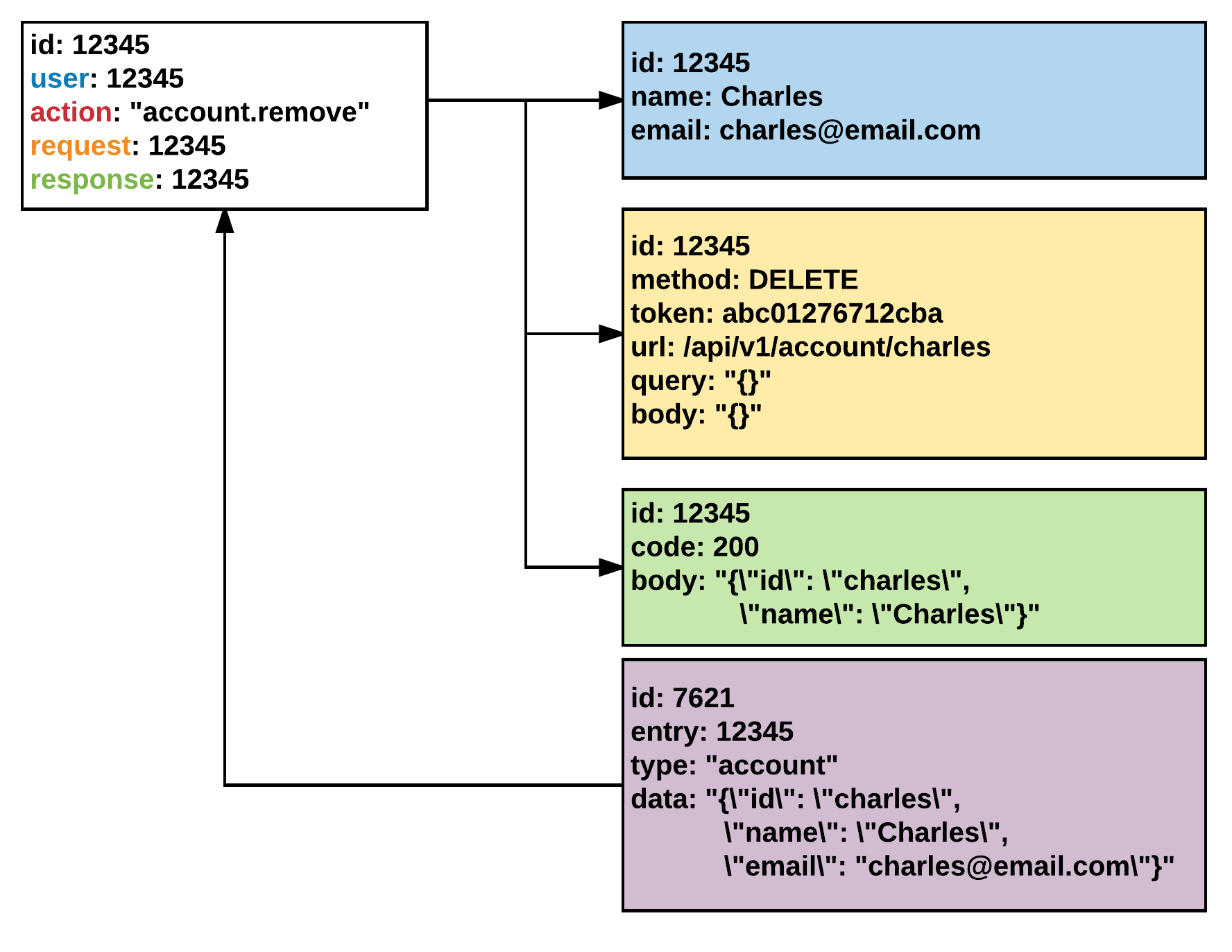
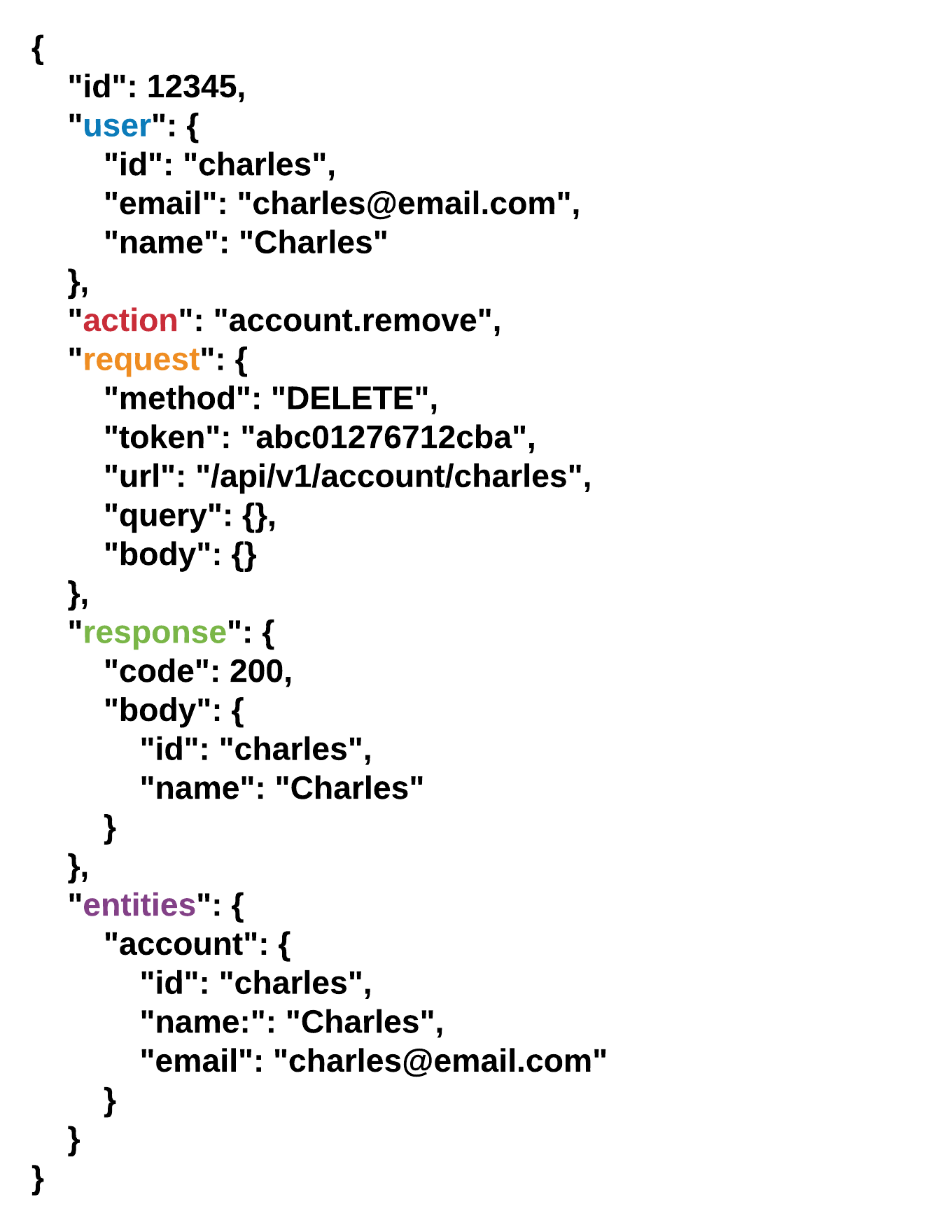
This makes questions like "How many times did people make changes to the charles account entity?" almost impossible to answer safely and effectively in the relational case, while in the document case, one can simple issue a query like: db.audit.find({ "entities.account.id": "charles" }).count().
The best approximation in a SQL query would be something like the following:
SELECT COUNT(a.id) FROM audit AS a
JOIN audit_entities AS e ON e.entry = a.id
WHERE e.type = 'account' AND e.data LIKE '%"id": "charles"%'
Unfortunately, this breaks the moment your JSON formatting removes the space and imposes a costly string search on every account entry to determine matching audit logs. This becomes even more costly if it is a common operation, while in the document case one can simply add a sparse index on entities.account.id.
Consumer Dictated Data Structures
If you're building a data storage service in which your consumers dictate the format of the data but expect the ability to query or perform atomic changes, relational databases become an extremely costly solution.
Let's take the example of a system which provides a general API through which data can be stored. Consumers expect to be able to query that data based on a number of different fields, determined by them, as well as make changes to specific fields under the guarantee of atomicity.
Design Exercise
Let's run through a quick design exercise in which we build a feature-compatible set of implementations for unstructured (according to the implementation) data persistence on both document and relational databases.
Our API will look something like the following...
API
Create a Document
POST /api/v1/c/my_collection HTTP/1.1
Content-Type: application/json; charset=utf-8
{
"x": 1,
"y": 2
}
HTTP/1.1 201 Created
Content-Type: application/json; charset=utf-8
{
"id": 1,
"x": 1,
"y": 2
}
Update a Document
PATCH /api/v1/c/my_collection/1 HTTP/1.1
Content-Type: application/json; charset=utf-8
{
"z": 3
}
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"id": 1,
"x": 1,
"y": 2,
"z": 3
}
Get a Document
GET /api/v1/c/my_collection/1 HTTP/1.1
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"id": 1,
"x": 1,
"y": 2
}
Find Documents
GET /api/v1/c/my_collection?x=1 HTTP/1.1
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
[
{
"id": 1,
"x": 1,
"y": 2
}
]
Document Implementation
The document implementation is effectively trivial, we simply rely on the functionality provided by the document database to do all the heavy lifting.
def create_document(self, req):
collection = self.db[req.params.collection]
result = collection.insert(req.body)
return result.inserted
def get_document(self, req):
collection = self.db[req.params.collection]
return collection.find_one({ "id": req.params.id })
def update_document(self, req):
collection = self.db[req.params.collection]
collection.update({ "id": req.params.id }, req.body)
return self.get_document(req)
def find_documents(self, req):
collection = self.db[req.params.collection]
return collection.find(req.query)
This implementation obviously ignores the intricacies of error handling and data validation, but it would work almost out of the box with most document datastores.
Relational Implementation
On the other hand, the relational implementation would require us to do something approximating the following:
CREATE TABLE entry (
ID int primary key auto_increment,
collection varchar(255) not null
)
CREATE TABLE field (
ID int primary key auto_increment,
entry int not null,
key varchar(255) not null,
value text,
CONSTRAINT FK_entry FOREIGN KEY(entry) REFERENCES entry(ID),
CONSTRAINT UQ_key UNIQUE (entry, key)
)
In this configuration, we have a one to many relationship between arbitrary field item and a corresponding entry.
import json
# NB: Don't use this code in production, it doesn't do anything to protect
# against SQL injection or to handle errors. It's just a rough example to
# convey an idea.
def create_document(self, req):
entry_id = self.db.run("INSERT INTO entry(collection) VALUES ('{0}')".format(req.params.collection))
for field in self.get_fields(req.body):
self.db.run("INSERT INTO field(entry, key, value) VALUES({0}, '{1}', '{2}')".format(
entry_id,
field.key,
json.dumps(field.value)
))
def get_document(self, req):
fields = self.db.run(
f"SELECT field.key, field.value FROM field JOIN entry ON entry.ID = field.entry WHERE entry.collection = '{req.params.collection}' AND entry.ID = {req.params.id}")
data = {
"id": req.params.id
}
for field in fields:
self.set_field(data, field.key, json.loads(field.value))
return data
def update_document(self, req):
# if we ignore the collection<->id relationship, we can make it a bit shorter
for field in self.get_fields(req.body):
self.db.run("UPDATE field SET value = '{2}' WHERE entry = '{0}' AND key = '{1}'".format(
req.params.id,
field.key,
field.value
))
return self.get_document(req)
def find_documents(self, req):
entry_query = ""
for field in self.get_fields(req.body):
query = "SELECT id FROM field WHERE key = '{0}' AND value = '{1}'".format(field.key, json.dumps(field.value))
if entry_query != "":
entry_query = query + " INTERSECT " + entry_query
else:
entry_query = query
entry_ids = self.db.run(entry_query)
entries = []
for eid in entry_ids:
fields = self.db.run(
f"SELECT field.key, field.value FROM field JOIN entry ON entry.ID = field.entry WHERE entry.collection = '{req.params.collection}' AND entry.ID = {req.params.id}")
data = {
"id": req.params.id
}
for field in fields:
self.set_field(data, field.key, json.loads(field.value))
entries.append(data)
return entries
Even after all that, the relational implementation is still liable to break in weird and wonderful ways that the document implementation would not. It is vulnerable to SQL injection attacks, makes many more queries for the same operation than the document DB would and must store significantly more data to describe even basic data structures.
One could argue that you could instead develop schemas for the client, potentially having the client register their data schema with your service and generating tables for it. My response to that is simply "Why?" - if you need to store data for which you don't know the schema at development time, adopt tooling which supports your use case and data structures.
Beyond that, there is the matter of complexity. I'm fairly confident that anybody reading this blog can read and understand exactly what is going on in the Document DB implementation. On the other hand, the relational implementation is rather complex, it's using INTERSECTs, flattening and deepening dictionaries, does JOINs to enforce a layer of safety - and all that before we start defending against SQL injection or handling errors...
Conclusion
To close out this post, it's imperative that you understand the limitations and benefits of various datastores before making a decision regarding the correct one for your application. Certain datastores are better suited to rapid, evolutionary development or the storage of semi-structured data, while others offer feature sets better suited to systems where persisted data is the primary component of the system.
While most databases can solve most problems adequately, there are numerous benefits to selecting a data representation and storage engine which places the correct emphasis on schema ownership for your specific use case. When considering systems which must serve many thousands of requests per second, it is also important to consider data locality as a factor, more so in situations where one must shard their data to meet size, performance or cost constraints.
At the end of the day, there is no perfect database for every problem. Each attempts to solve specific problems and address specific use cases. By selecting a database which matches your problem domain you can reduce the cost of development substantially, deliver higher quality software and more reliably meet cost and time deadlines.